Modern data teams are cross-functional groups that turn raw data into reliable insights and production features by combining engineers, analysts, scientists, architects, and ML specialists. This matters because your company’s ability to act on data depends less on a single tool and more on how these roles collaborate across ingestion, transformation, analysis, modeling, deployment, and governance. In this article you'll learn what each role does, how the lifecycle flows, which tools form a modern stack, operating models that scale, governance and quality best practices, and practical hiring and career tips to help your team deliver measurable business value.
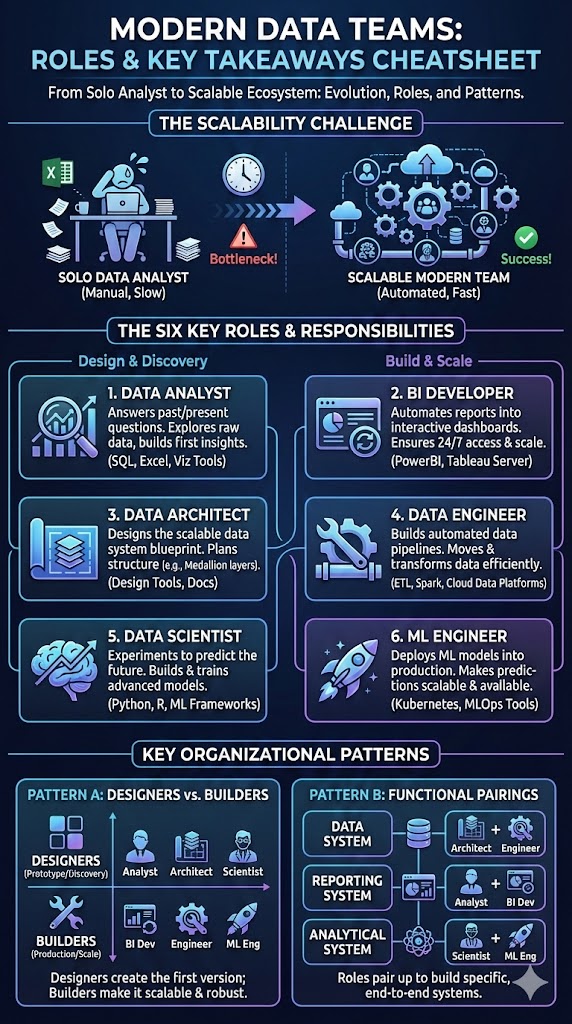
Core roles in modern data teams: data engineers, analysts, scientists, architects, ML
Data engineers & analytics engineers — responsibilities and deliverables
Ask: who keeps data reliable and available? You rely on data engineers to build ingestion pipelines, manage warehouses or lakehouses, and ensure data freshness. Analytics engineers sit between engineering and analysis: they own semantic models, tests, and transformation code (dbt-style). Actionable tip: implement automated tests (schema, null checks, freshness) in CI so new sources don't break downstream reports.
Data analysts & BI specialists — metrics, dashboards, and stakeholder partnerships
Imagine getting a question from Sales and shipping an insight within a day; that’s the analyst’s value. Analysts define KPIs, create dashboards, and translate stakeholder needs into queries and visualizations. Example: build a canonical metrics layer to avoid conflicting churn numbers across teams. Actionable tip: pair analysts with a product owner for a two-week sprint to deliver high-impact dashboards.
Data scientists, ML engineers & data architects — modeling, production, and platform design
You need data scientists to discover patterns and validate hypotheses, ML engineers to productionize models, and architects to design scalable schemas and governance. Practical insight: require model cards and performance baselines before production deployment so retraining and rollback are tractable.
- Use clear ownership: pipelines = engineers; models = scientists + ML engineers; metrics = analysts.
- Document SLAs for freshness, accuracy, and uptime for each dataset used in production.
- Adopt semantic layers so analysts and scientists share a single source of truth.
| Role | Focus | Key Skills | Deliverable | Example Metric |
|---|---|---|---|---|
| Data Engineer | Reliability & ingestion | SQL, Python, ETL/ELT | Pipelines, schemas | Data freshness (hours) |
| Analytics Engineer | Modeling & transformations | dbt, SQL, testing | Semantic models | Test coverage % |
| Data Analyst | Reporting & insights | SQL, viz, storytelling | Dashboards | Dashboard adoption |
| Data Scientist | Experimentation & models | ML, stats, Python | Models, experiments | Prediction AUC |
| ML Engineer | Deployment & monitoring | APIs, infra, MLOps | Model endpoints | Latency, error rate |
| Data Architect | Platform & governance | Modeling, systems | Platform designs | Cost per TB |
Collaboration across the data lifecycle in a modern data team
Ingestion & storage — ownership of sources, pipelines, and lake/warehouse onboarding
Who does source onboarding? Usually data engineers, but success depends on clear contracts. Start by cataloging sources with owners, frequency, and SLAs. Example: require every new source to include an owner, sample rows, and a retention policy before onboarding. Actionable insight: run a three-week nudged onboarding process that includes a validation checklist and a signed data contract to avoid downstream confusion.
Transformation & modeling — analytics engineering, feature engineering, and shared semantic layers
Want reproducible analytics? Use transformation-as-code and shared semantic layers so analysts, scientists, and product teams query the same definitions. Example: adopt dbt for transformations and store canonical metrics in a metrics layer. Actionable steps: enforce pull-request reviews for model changes and keep transformations modular so features can be reused across models.
Analysis, ML, and consumption — experiments, model deployment, monitoring, and feedback loops
How do experiments become features? Data scientists prototype models, ML engineers productionize them, and analysts track business impact. Make feedback loops explicit: production model drift triggers a triage runbook and a data quality incident. Actionable tip: integrate model monitoring with alerting and connect alerts to a rotation schedule so someone is always on-call.
- Define dataset contracts with freshness and completeness SLAs.
- Use a staging environment for schema changes and production shadow runs for models.
- Share retrospectives after incidents to improve contracts and tests.
Modern data stack, tools, and architecture for data teams
Core platform: data warehouses, lakes, lakehouses, and cloud architecture
Which storage should you pick? Warehouses (Snowflake, BigQuery) excel at analytics, lakes excel at raw capture, and lakehouses combine both. Example: many teams use a lake to land raw events and a warehouse for modeled analytics. Actionable insight: choose a primary compute engine early and design data schemas to minimize cross-system joins.
Integration & orchestration: ETL/ELT, streaming, eventing, and orchestration tools
Need reliable pipelines? Use ELT patterns to load raw data quickly, then transform in the warehouse. Tools like Airflow, Prefect, or managed orchestration automate scheduling and retries. For high-volume events, add streaming with Kafka or Pub/Sub. Actionable tip: centralize scheduling logic and use templated DAGs to reduce duplicated complexity.
ML infra & observability: feature stores, model serving, monitoring, and lineage tools
Want trustworthy models in production? Use feature stores to enforce consistency between training and serving, model serving frameworks for low-latency inference, and observability tools to track performance drift and lineage. Actionable step: require feature tests that validate training-serving parity before model deployment.
| Layer | Common Tools | Why it helps |
|---|---|---|
| Warehouse/Lakehouse | Snowflake, BigQuery, Databricks | Fast analytics and scalable storage |
| Transformation | dbt, Spark, SQL | Versioned, tested models |
| Orchestration | Airflow, Prefect, Dagster | Reliable scheduling |
| Streaming | Kafka, Pub/Sub, Kinesis | Real-time events |
| Feature Store & MLOps | Feast, Tecton, MLflow | Training-serving parity |
| Observability | Monte Carlo, Datadog, Prometheus | Detect drift & incidents |
Operating models, org structure, and processes for high-performing data teams
Centralized vs decentralized vs federated data team models and when to use them
Which model fits you? Centralized teams keep expertise and standards in one group, ideal for small-to-medium orgs that need tight governance. Decentralized teams embed analysts and engineers in product teams for speed but risk duplication. Federated models combine both: a central platform team provides tools and standards while domain-aligned squads deliver product-focused analytics. Actionable framework: if you have >5 product teams, move to a federated model with a central platform to avoid duplicated infra costs.
Delivery processes: DataOps, CI/CD for data, testing, and reproducible pipelines
How can you ship reliably? Implement DataOps practices: automated testing for transformations, CI for dbt and ML pipelines, and reproducible environments via containerization. Example checklist: unit tests for SQL models, integration tests for pipelines, and end-to-end smoke tests for dashboards. Actionable tip: enforce PR reviews and automated test gates before merging to production branches.
Prioritization, SLAs, and cross-functional contracting with product and business teams
Want to align priorities? Use a lightweight contract between data and business: define outcomes, success metrics, timelines, and maintenance responsibilities. Example: a quarterly roadmap with committed SLAs for dataset freshness and dashboard delivery builds trust. Actionable step: run a monthly sync between data leads and product managers to re-prioritize based on impact and capacity.
Data governance, quality, security, and reliability for modern teams
Data governance & metadata: ownership, catalogs, data contracts, and discoverability
Who owns each dataset? Assign dataset owners and publish metadata in a catalog so you can discover lineage, owners, and usage. Use data contracts to codify expectations (freshness, schema, access). Actionable tip: require dataset owner fields in the catalog and link dashboards back to source tables for traceability.
Data quality engineering: tests, anomaly detection, lineage, and incident response
How do you detect bad data early? Build layered quality checks: unit tests in transformations, monitoring for anomalies, and lineage to find root causes. Example practice: auto-create incidents when row counts or cardinality deviate by >20% versus baseline and assign triage to the owner within one business day. Actionable step: maintain a runbook that maps alerts to who fixes what and how to roll back faulty transformations.
Security, privacy, and compliance: access controls, masking, and regulatory requirements
Need to protect sensitive data? Implement role-based access controls, column-level masking, and strict logging. For regulated data (PII, PCI, HIPAA), apply encryption at rest and in transit and keep an audit trail. Actionable advice: use automated scans to tag sensitive fields and enforce masking in downstream environments.
- Catalog datasets with owners, PII flags, and SLA fields.
- Automate tests and alerts to catch regressions early.
- Document incident playbooks and run regular tabletop exercises.
Hiring, skills development, career paths, and the future of data teams
Role-specific hiring criteria & core technical/soft skills for each data role
Who to hire first? For early-stage teams hire a strong data engineer and an analytics-focused analyst. Look for: data engineers with ETL/ELT experience, cloud SQL skills, and pipeline testing fluency; analytics engineers comfortable with dbt and testing; analysts with storytelling and SQL fluency; data scientists with experimental design and model validation skills; ML engineers familiar with serving and monitoring; architects with system-level thinking. Soft skills: communication, domain curiosity, and collaboration matter more than spot technical tricks.
Career ladders, upskilling, mentorship, and enabling cross-role mobility
Want to retain talent? Create clear ladders tying technical scope to business impact. Offer rotational programs so analysts shadow engineers for a quarter or ML engineers pair with data scientists on model pipelines. Actionable idea: run monthly brown-bag sessions where team members demo a pipeline, dashboard, or model and share lessons learned.
Trends shaping modern data teams: automation, MLOps, generative AI, and evolving org needs
What should you prepare for? Expect more automation in pipeline creation, stronger MLOps practices, and new productivity gains from generative AI for code and analyses. Architects will prioritize modular, observability-first platforms, and teams will emphasize interoperability. Actionable preparation: adopt modular tooling, invest in observability early, and pilot generative AI for templating analyses while safeguarding governance and review processes.
- Prioritize cross-training to reduce single-point dependencies.
- Invest in MLOps pipelines and model monitoring from day one for production models.
- Use mentorship and rotations to build empathetic, collaborative teams.
Modern data teams succeed when roles are clear, collaboration is structured, and platforms are reliable and observable. Start by mapping owners and SLAs, invest in transformation-as-code and test automation, and create feedback loops between analysts, scientists, and ML engineers so models and dashboards stay useful. Actionable next steps: (1) run a two-week audit of your top 10 datasets to assign owners and SLAs, (2) enable a CI pipeline for transformations and tests, and (3) pilot a federated model if you support multiple product domains. These steps will help you move faster while reducing downstream incidents and confusion. Remember: modern data teams are about people and processes as much as tools — focus on clear contracts, shared definitions, and continuous learning so your team turns data into consistent business value.